LLM Naming Explained (What do the options mean?)

Model Naming Explained
You've browsed the Ollama homepage and are unsure of which model to download. There are a bunch of options: Like should you get the q4_K_M or fp16? What does this all mean?
Luckily most models follow a similar naming convention. For example, let's look at a Llama model series:
llama3.3-70b-instruct-q4_K_M model name - number of parameters - fine-tuned type - quantization type
Parameters
This is the 70b model which means 70 billion, which is an indication of the capacity and complexity of the model. Higher numbers typically perform better but also require better hardware.
Instruction Model
An instruction model is a type of large language model that has been fine-tuned to closely follow instructions or prompts given by the user. If you want to chat with it like ChatGPT, then an instruct model is probably the best choice.
Quantization Type
Quantization is used to compress the model. There are different levels to it. Q4 stands for 4-bit quantization. It's a good balance between performance and accuracy.
Some types explained:
- fp16 - is full precision 16-bit floating point. This is the least compressed and highest quality, hence the massive file size.
- q - refers to the quantization levels.
- This model has q2 all the way to q8. Higher levels require more memory.
- Suffixes:
- 0 or 1 - uniform quantization
- K - refers to the quantization method K-quant
- (_S, _M, _L) Small, Medium or Large - Block size (small: low memory usage, lower precision)
If not specified, it's usually q4_K_M by default.
Quantization is similar to watching a 1080p video vs. a 720p video vs. 480p. You are making tradeoffs between quality (resolution) vs. size/accuracy.
Higher quantization can give you better results but may require more computing power. For most use cases, you want to go for q4_K_M, which offers a good balance between performance and accuracy. This is also the default quantization for most models.
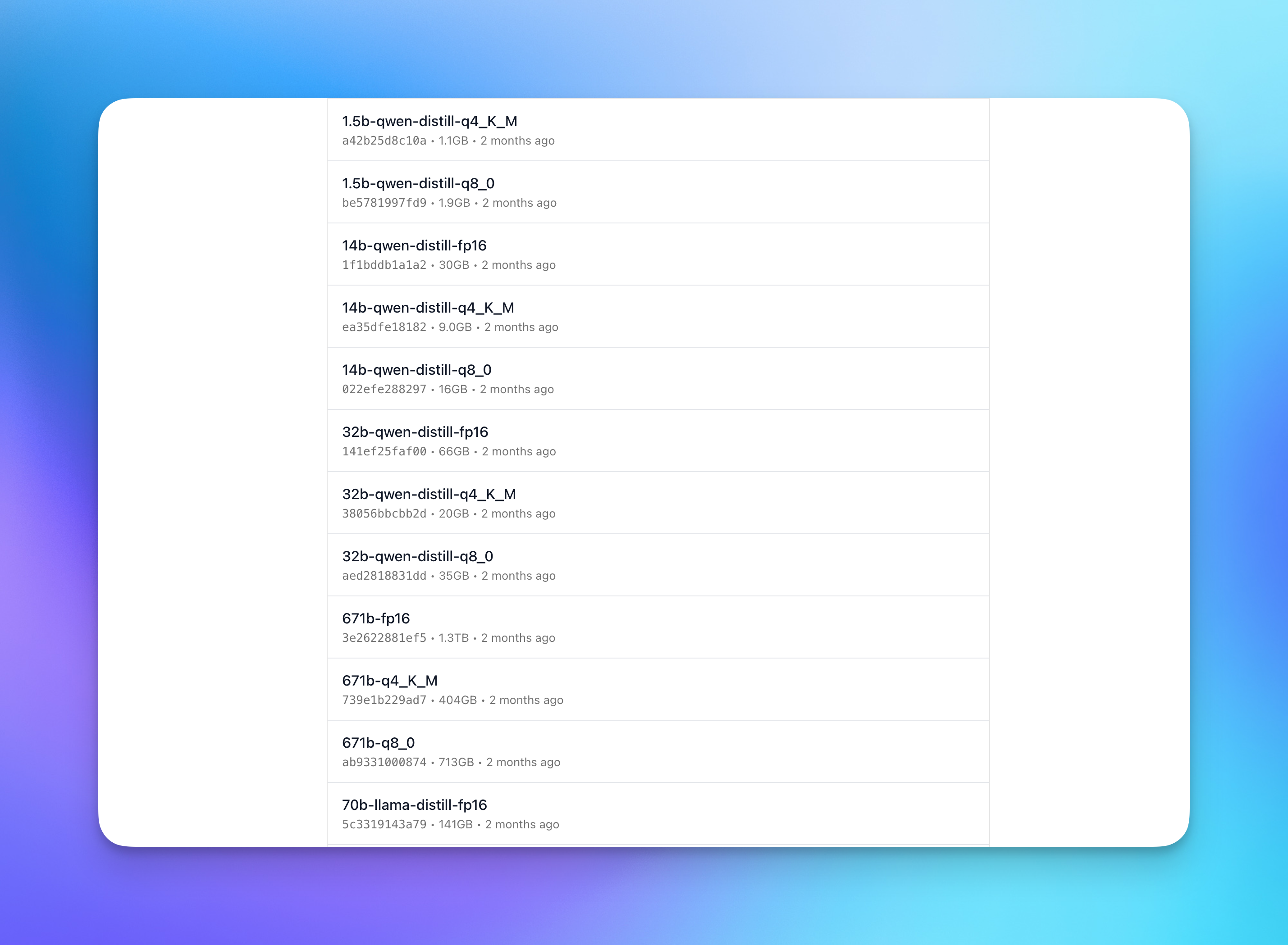
Here's a table with what the values mean:
| Category | Size | Quantization Method | Quality Impact | Recommendation |
|---|---|---|---|---|
| Q2_K | smallest | K-quant | extreme quality loss | Not Recommended |
| Q3_K/Q3_K_M | very small | K-quant | very high quality loss | Not Recommended |
| Q3_K_S | very small | K-quant | very high quality loss | Not Recommended |
| Q4_0 | small | Uniform | very high quality loss | prefer using Q3_K_M |
| Q4_1 | small | Uniform | substantial quality loss | prefer using Q3_K_L |
| Q4_K_S | small | K-quant | significant quality loss | Not Recommended |
| Q4_K/Q4_K_M | medium | K-quant | balanced quality | Recommended |
| Q5_0 | medium | Uniform | balanced quality | prefer using Q4_K_M |
| Q5_1 | medium | Uniform | low quality loss | prefer using Q5_K_M |
| Q5_K_S | large | K-quant | low quality loss | Recommended |
| Q5_K/Q5_K_M | large | K-quant | very low quality loss | Recommended |
| Q6_K | very large | K-quant | extremely low quality loss | Not Specified |
| Q8_0 | very large | Uniform | extremely low quality loss | Not Recommended |
| F16/FP16 | extremely large | N/A | virtually no quality loss | Not Recommended |
| F32/FP32 | absolutely huge | N/A | lossless | Not Recommended |
Now you should be able to tell
deepseek-r1:70b-llama-distill-q4_K_M
Oooh, that's the DeepSeek R1 70 billion parameter model distilled into Llama with q4 K-quantization of a medium size which offers a good balance between performance and accuracy.